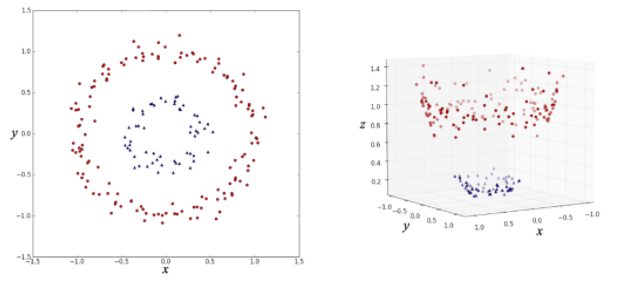
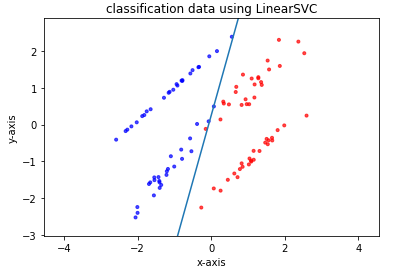
教師ありの機会学習の際の基本的な構造は以下のようになる
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 学習データとテストデータに分ける train_X, test_X, train_y, test_y = train_test_split(X,Y, random_state=42) # モデルの読み込み from sklearn.neighbors import KNeighborsClassifier # モデルの構築 model = KNeighborsClassifier()#学習内容によって変わる # モデルの学習 model.fit(train_X, train_y)#学習データがはいる # 正解率の表示 print(model.score(test_X, test_y))#テストデータが入る |