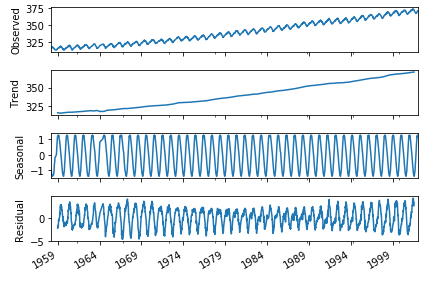
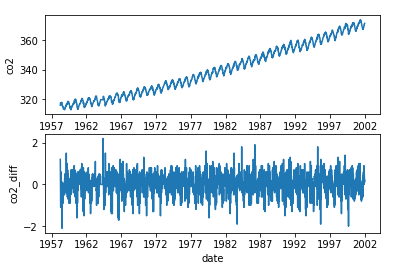
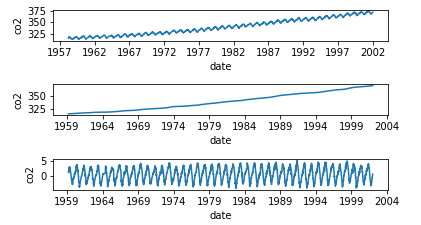
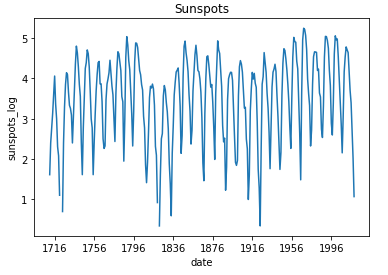
データを訓練用と訓練用に分ける
時系列分析の場合は前回のデータを基にするのでランダムにしない
一般的な分別の場合はランダムに分ける
◆一般的な分析の場合
|
1 2 3 4 |
y = data.quality X = data.drop('quality', axis=1) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,random_state=123,stratify=y) |
◆時系列分析の場合
前半67%を訓練用、残りはテスト用
|
1 2 3 4 |
train_size = int(len(dataset) * 0.67) test_size = len(dataset) - train_size train, test = dataset[0:train_size,:], dataset[train_size:len(dataset),:] print(len(train), len(test)) |