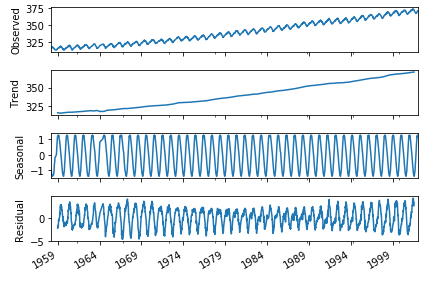
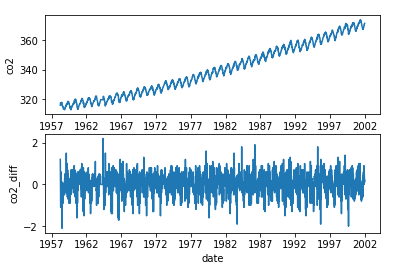
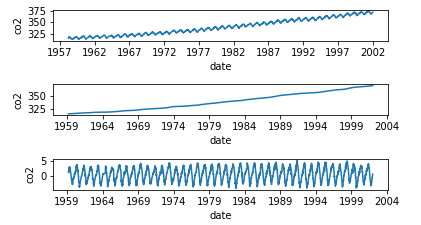
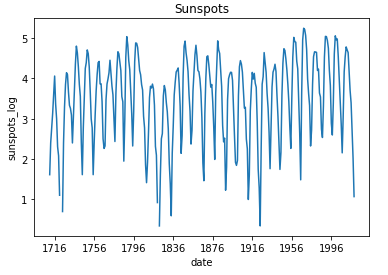
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
print(__doc__) import itertools import numpy as np import matplotlib.pyplot as plt from sklearn import svm, datasets from sklearn.model_selection import train_test_split from sklearn.metrics import confusion_matrix # import some data to play with iris = datasets.load_iris() X = iris.data y = iris.target class_names = iris.target_names # Split the data into a training set and a test set X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) # Run classifier, using a model that is too regularized (C too low) to see # the impact on the results classifier = svm.SVC(kernel='linear', C=0.01) y_pred = classifier.fit(X_train, y_train).predict(X_test) def plot_confusion_matrix(cm, classes, normalize=False, title='Confusion matrix', cmap=plt.cm.Blues): """ This function prints and plots the confusion matrix. Normalization can be applied by setting `normalize=True`. """ if normalize: cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis] print("Normalized confusion matrix") else: print('Confusion matrix, without normalization') print(cm) plt.imshow(cm, interpolation='nearest', cmap=cmap) plt.title(title) plt.colorbar() tick_marks = np.arange(len(classes)) plt.xticks(tick_marks, classes, rotation=45) plt.yticks(tick_marks, classes) fmt = '.2f' if normalize else 'd' thresh = cm.max() / 2. for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])): plt.text(j, i, format(cm[i, j], fmt), horizontalalignment="center", color="white" if cm[i, j] > thresh else "black") plt.tight_layout() plt.ylabel('True label') plt.xlabel('Predicted label') # Compute confusion matrix cnf_matrix = confusion_matrix(y_test, y_pred) np.set_printoptions(precision=2) # Plot non-normalized confusion matrix plt.figure() plot_confusion_matrix(cnf_matrix, classes=class_names, title='Confusion matrix, without normalization') # Plot normalized confusion matrix plt.figure() plot_confusion_matrix(cnf_matrix, classes=class_names, normalize=True, title='Normalized confusion matrix') plt.show() |