|
1 2 3 4 5 6 7 8 9 10 11 |
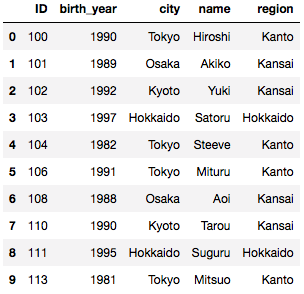
<span class="cm-keyword">import</span> <span class="cm-variable">pandas</span> <span class="cm-keyword">as</span> <span class="cm-variable">pd</span> <span class="cm-keyword">from</span> <span class="cm-variable">pandas</span> <span class="cm-keyword">import</span> <span class="cm-variable">DataFrame</span> <span class="cm-variable">attri_data1</span> = {<span class="cm-string">'ID'</span>: [<span class="cm-string">'100'</span>, <span class="cm-string">'101'</span>, <span class="cm-string">'102'</span>, <span class="cm-string">'103'</span>, <span class="cm-string">'104'</span>, <span class="cm-string">'106'</span>, <span class="cm-string">'108'</span>, <span class="cm-string">'110'</span>, <span class="cm-string">'111'</span>, <span class="cm-string">'113'</span>] ,<span class="cm-string">'city'</span>: [<span class="cm-string">'Tokyo'</span>, <span class="cm-string">'Osaka'</span>, <span class="cm-string">'Kyoto'</span>, <span class="cm-string">'Hokkaido'</span>, <span class="cm-string">'Tokyo'</span>, <span class="cm-string">'Tokyo'</span>, <span class="cm-string">'Osaka'</span>, <span class="cm-string">'Kyoto'</span>, <span class="cm-string">'Hokkaido'</span>, <span class="cm-string">'Tokyo'</span>] ,<span class="cm-string">'birth_year'</span> :[<span class="cm-number">1990</span>, <span class="cm-number">1989</span>, <span class="cm-number">1992</span>, <span class="cm-number">1997</span>, <span class="cm-number">1982</span>, <span class="cm-number">1991</span>, <span class="cm-number">1988</span>, <span class="cm-number">1990</span>, <span class="cm-number">1995</span>, <span class="cm-number">1981</span>] ,<span class="cm-string">'name'</span> :[<span class="cm-string">'Hiroshi'</span>, <span class="cm-string">'Akiko'</span>, <span class="cm-string">'Yuki'</span>, <span class="cm-string">'Satoru'</span>, <span class="cm-string">'Steeve'</span>, <span class="cm-string">'Mituru'</span>, <span class="cm-string">'Aoi'</span>, <span class="cm-string">'Tarou'</span>, <span class="cm-string">'Suguru'</span>, <span class="cm-string">'Mitsuo'</span>]} <span class="cm-variable">attri_data_frame1</span> = <span class="cm-variable">DataFrame</span>(<span class="cm-variable">attri_data1</span>) <span class="cm-variable">attri_data_frame1</span> |

もう一つの辞書を追加
|
1 2 3 4 5 6 7 8 |
<span class="cm-variable">city_map</span> ={<span class="cm-string">'Tokyo'</span>:<span class="cm-string">'Kanto'</span> ,<span class="cm-string">'Hokkaido'</span>:<span class="cm-string">'Hokkaido'</span> ,<span class="cm-string">'Osaka'</span>:<span class="cm-string">'Kansai'</span> ,<span class="cm-string">'Kyoto'</span>:<span class="cm-string">'Kansai'</span>} </code><code class="cm-s-ipython language-python"><span class="cm-variable">city_map</span></code><code class="cm-s-ipython language-python"><span class="cm-variable"> 最初のattri_data_frame1のcityカラムを対象とし、</span> |
|
1 2 |
<span class="cm-variable">そのカラムの文字列、数値に一致するカラムを追加していく </span> |
|
1 2 3 4 5 6 |
<span class="cm-comment">対応するデータがない場合はNaNになる </span> </code><code class="cm-s-ipython language-python"><span class="cm-variable">attri_data_frame1</span></code><code class="cm-s-ipython language-python">[<span class="cm-string">'region'</span>] = <span class="cm-variable">attri_data_frame1</span>[<span class="cm-string">'city'</span>].<span class="cm-property">map</span>(<span class="cm-variable">city_map</span>) <span class="cm-variable">attri_data_frame1</span> |
出力結果
cityに合わせてregionが追加されている