US CENSUSの人口データを使用して
CSVのデータをデータフレームに入れて色々操作します。
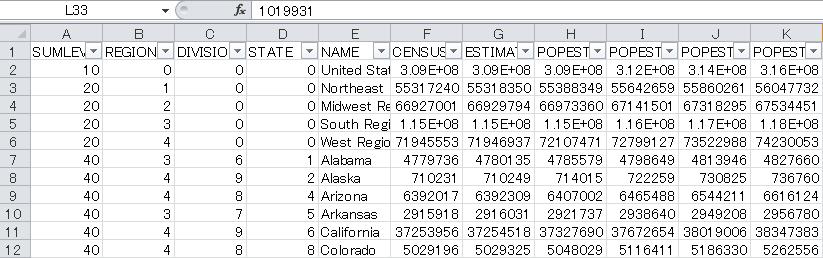
使用するCSVデータ:nst-est2017-alldata-1.csv
Contents
インポートして上5行を表示
|
1 2 3 4 5 6 |
import pandas as pd import plotly.offline as pyo import plotly.graph_objs as go df = pd.read_csv("nst-est2017-alldata.csv") print(df.head()) |
エクセルでいうフィルター
df2という名称のデータフレームに分けて
カラムがDIVISIONでありかつ値が1の物だけを入れる
|
1 |
df2 = df[df["DIVISION"] == "1"] |

列の一つをインデックスに割り当て
カラムNAMEとその列の値を行に変換する
|
1 |
df2.set_index("NAME",inplace = True) |

左側にNAMEインデックスが作成されました
※マルチインデックスにするにはdf.set_index([“a”,”b”])とする
指定文字を含むカラムを抽出
“POP”という文字で始まるカラムのみを抽出
|
1 2 |
list_of_pop_col = [col for col in df2.columns if col.startswith("POP")] df2 = df2[list_of_pop_col] |
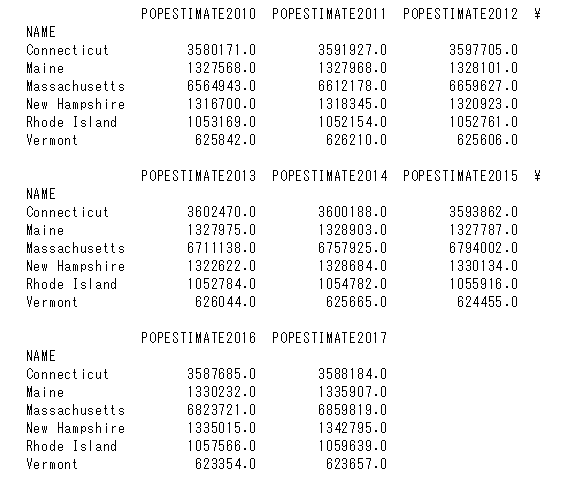
線グラフにして出力
|
1 2 3 4 5 6 |
data = [go.Scatter(x=df2.columns, y=df2.loc[name], mode="lines", name=name) for name in df2.index] pyo.plot(data) |
上記コードの詳細を以下に記載します。
x軸の指定
x=df2.columnsとなっているのはx軸に各カラムの名前を入れていく
作業になります。

y軸の指定
y=df2.loc[name]と指定しています。
[go.Scatter…]の最後にfor name in df2.indexとあるので
先程df2.set_index(“NAME”,inplace = True)にて設定した
インデックスの数だけ繰り返す形になります。

上記6種類のインデックスがあるので6回繰り返して
地名をnameに代入します。
代入されたnameの地名に該当する値をデータフレームの
左から右に読み込んでいきます。
グラフの種類指定
|
1 |
mode="lines" |
“lines”を指定して線グラフにします。
各グラフの名前指定
|
1 |
name=name |
for name in df2.indexでインデックスにある地名をnameに代入し、
これによって出力されたグラフに各線グラフの名称が
表示されるようになります。
コード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import pandas as pd import plotly.offline as pyo import plotly.graph_objs as go df = pd.read_csv("nst-est2017-alldata.csv") print(df.head()) df2 = df[df["DIVISION"] == "1"] df2.set_index("NAME",inplace = True) list_of_pop_col = [col for col in df2.columns if col.startswith("POP")] df2 = df2[list_of_pop_col] data = [go.Scatter(x=df2.columns, y=df2.loc[name], mode="lines", name=name) for name in df2.index] pyo.plot(data) |
出力されたグラフ
曜日別にforで作成するグラフ
グラフの線を曜日別に表示する
以下の例ではわかりやすくする為df2を作成し、
forが回る度に曜日別のデータをgo.Scatterで入れていきます。
|
1 2 3 4 5 6 7 |
for day in days: df2 = df[df["DAY"] == day] trace = go.Scatter(x=df2["LST_TIME"], y=df2["T_HR_AVG"], mode="lines", name = day) data.append(trace) |
もう少しすっきりさせるには以下のようにします。
|
1 2 3 4 5 6 |
for day in days: trace = go.Scatter(x=df["LST_TIME"], y=df[df["day"]==day]["T_HR_AVG"], mode="lines", name = day) data.append(trace) |
高度な書き方だとforを使用せず辞書に曜日別データを入れていきます。
|
1 2 3 4 5 |
data = [{ "x":df["LST_TIME"], "y":df[df["DAY"]==day]["T_HR_AVG"], "name":day } for day in df["DAY"].unique()] |
コード
使用するCSVデータ:2010YumaAZ.csv
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
import pandas as pd import plotly.offline as pyo import plotly.graph_objs as go # Create a pandas DataFrame from 2010YumaAZ.csv df = pd.read_csv("2010YumaAZ.csv") days = ['TUESDAY','WEDNESDAY','THURSDAY','FRIDAY','SATURDAY','SUNDAY','MONDAY'] # Use a for loop (or list comprehension to create traces for the data list) # data = [] for day in days: df2 = df[df["DAY"] == day] trace = go.Scatter(x=df2["LST_TIME"], y=df2["T_HR_AVG"],#あるいはdf2を作らずにy=df[df["day"]==day]["T_HR_AVG"],としてもよい mode="lines", name = day) data.append(trace) # Define the layout layout = go.Layout(title="Daily temp avgs") # Create a fig from data and layout, and plot the fig fig = go.Figure(data=data,layout=layout) pyo.plot(fig) |
コメントを残す