|
1 2 |
|
1 2 3 4 5 6 7 8 9 10 |
import numpy as np from numpy import nan as NA import pandas as pd aa = pd.DataFrame(np.random.rand(10,4)) #一部のデータNanにする sample_data_frame.iloc[1,0] = NA sample_data_frame.iloc[2,2] = NA sample_data_frame.iloc[5:,3] = NA |
fillna()を用いると、引数として与えた数をNaNの部分に代入、
この例では0を代入
|
1 2 |
sample_data_frame.fillna(0) |
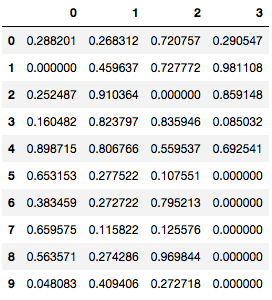
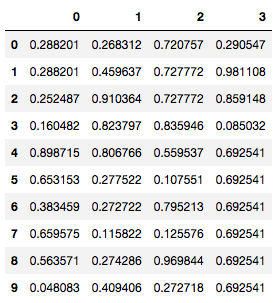
methodをにffillを指定し、上の値がそのままコピーされる
|
1 2 |
<span class="cm-variable">sample_data_frame</span>.<span class="cm-property">fillna</span>(<span class="cm-variable">method</span>=<span class="cm-string">"ffill"</span>) |
|
1 2 3 4 5 |
#欠損値処理 df['Fare'] = df['Fare'].fillna(df['Fare'].median())#Fareの平均値を代入 df['Age'] = df['Age'].fillna(df['Age'].median())#Ageの平均値を代入 df['Embarked'] = df['Embarked'].fillna('S')#Embarkedの値はQ,O,Sのどれかなので代表的なSを代入 df=df.dropna(subset=['Age'])#AgeのカラムにNanがある物を削除 |
コメントを残す