k-means法でのクラスタリング
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
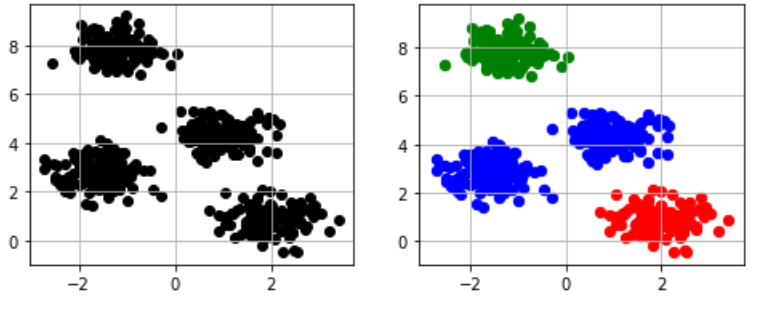
import matplotlib.pyplot as plt import numpy as np from sklearn.cluster import KMeans from sklearn.datasets import make_blobs # Xには1つのプロットの(x,y)が、yにはそのプロットの所属するクラスター番号が入る X,y = make_blobs(n_samples=150, # サンプル点の総数 n_features=2, # 特徴量(次元数)の指定 default:2 centers=3, # クラスタの個数 cluster_std=0.5, # クラスタ内の標準偏差 shuffle=True, # サンプルをシャッフル random_state=0) # 乱数生成器の状態を指定 km = KMeans(n_clusters=3, random_state=0) y_km = km.fit_predict(X) fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(8,3)) ax1.scatter(X[:, 0], X[:, 1], c='black') ax1.grid() ax2.scatter(X[y_km==0, 0], X[y_km==0, 1], c='r', s=40, label='cluster 1') ax2.scatter(X[y_km==1, 0], X[y_km==1, 1], c='b', s=40, label='cluster 2') ax2.scatter(X[y_km==2, 0], X[y_km==2, 1], c='g', s=40, label='cluster 3') ax2.grid() plt.show() |
コメントを残す