k-NNはk近傍法とも呼ばれ、予測をするデータと類似したデータをいくつか見つけ、多数決により分類結果を決める手法です。
怠惰学習と呼ばれる学習の種類の一手法であり、学習コスト(学習にかかる計算量)が0であることが特徴です。
これまで紹介してきた手法とは違い、k-NNは教師データから学習するわけではなく、予測時に教師データを直接参照してラベルを予測します。
結果の予測を行う際に①教師データを予測に用いるデータとの類似度で並べ直し、②分類器に設定されたk個分のデータを類似度の高い順に参照し、③参照された教師データが属するクラスのなかで最も多かったものを予測結果として出力する
のがこのk-NNという手法です。
k-NNの特徴としては、前述の通り学習コストが0であること、アルゴリズムとしては比較的単純なものなのですが高い予測精度がでやすいこと、複雑な形の境界線も表現しやすいことが挙げられます。
欠点としては分類器に指定する自然数kの個数を増やしすぎると識別範囲の平均化が進み予測精度が下がってしまう点や、予測時に毎回計算を行うため教師データや予測データの量が増えると計算量が増えてしまい、低速なアルゴリズムとなってしまう点が挙げられます。
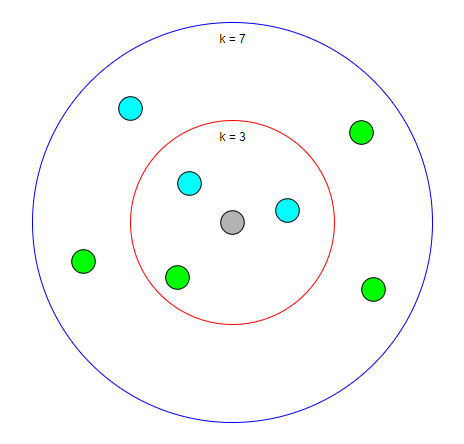
以下の画像は、kの数の違いによる分類過程の様子の違いを表しています。
灰色の点はk=3の時では水色の点の方が周りに多いため水色の点だと予測されますが、k=7の時では緑色の点の方が多いため緑色の点ではないかという予測に変わります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
# きのこデータの取得 import requests import zipfile from io import StringIO import io import pandas as pd from sklearn.model_selection import train_test_split from sklearn import preprocessing # url mush_data_url = "http://archive.ics.uci.edu/ml/machine-learning-databases/mushroom/agaricus-lepiota.data" s = requests.get(mush_data_url).content # データの形式変換 mush_data = pd.read_csv(io.StringIO(s.decode('utf-8')), header=None) # データに名前をつける(データを扱いやすくするため) mush_data.columns = ["classes", "cap_shape", "cap_surface", "cap_color", "odor", "bruises", "gill_attachment", "gill_spacing", "gill_size", "gill_color", "stalk_shape", "stalk_root", "stalk_surface_above_ring", "stalk_surface_below_ring", "stalk_color_above_ring", "stalk_color_below_ring", "veil_type", "veil_color", "ring_number", "ring_type", "spore_print_color", "population", "habitat"] # 参考(カテゴリー変数をダミー特徴量として変換する方法) mush_data_dummy = pd.get_dummies( mush_data[['gill_color', 'gill_attachment', 'odor', 'cap_color']]) # 目的変数:flg立てをする mush_data_dummy["flg"] = mush_data["classes"].map( lambda x: 1 if x == 'p' else 0) # 説明変数と目的変数 X = mush_data_dummy.drop("flg", axis=1) Y = mush_data_dummy['flg'] # 学習データとテストデータに分ける train_X, test_X, train_y, test_y = train_test_split(X,Y, random_state=42) # モデルの読み込み from sklearn.neighbors import KNeighborsClassifier # モデルの構築 model = KNeighborsClassifier() # モデルの学習 model.fit(train_X, train_y) # 正解率の表示 print(model.score(test_X, test_y)) |
コメントを残す