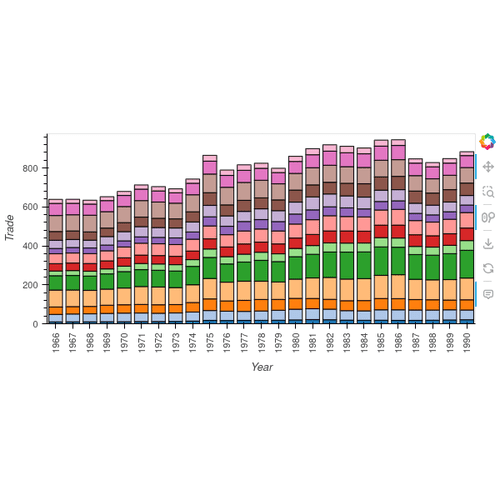
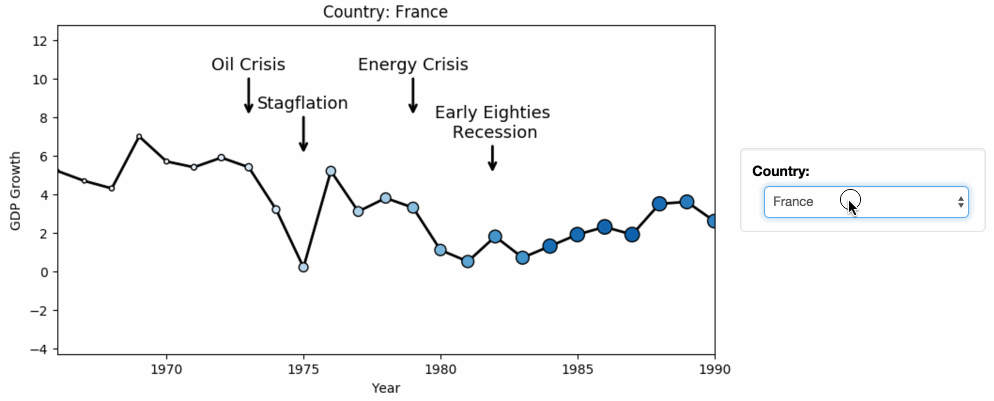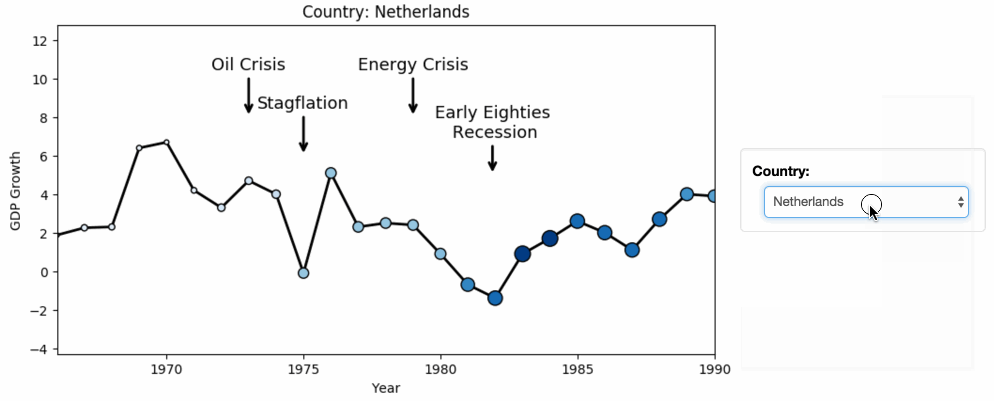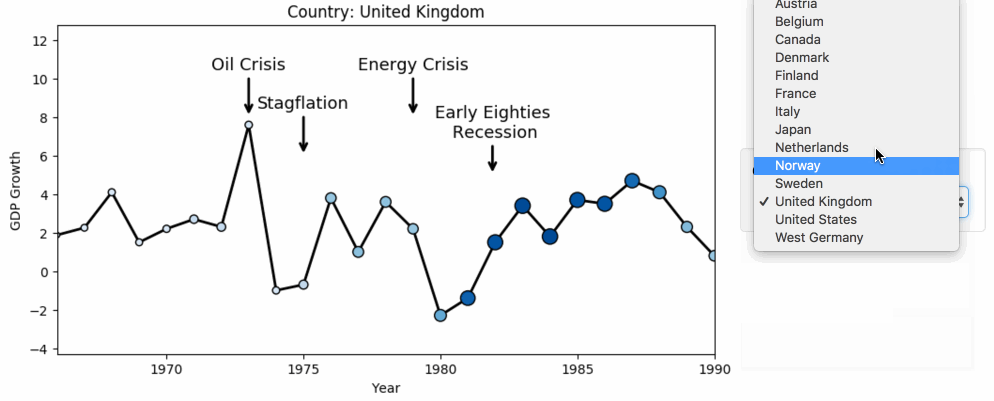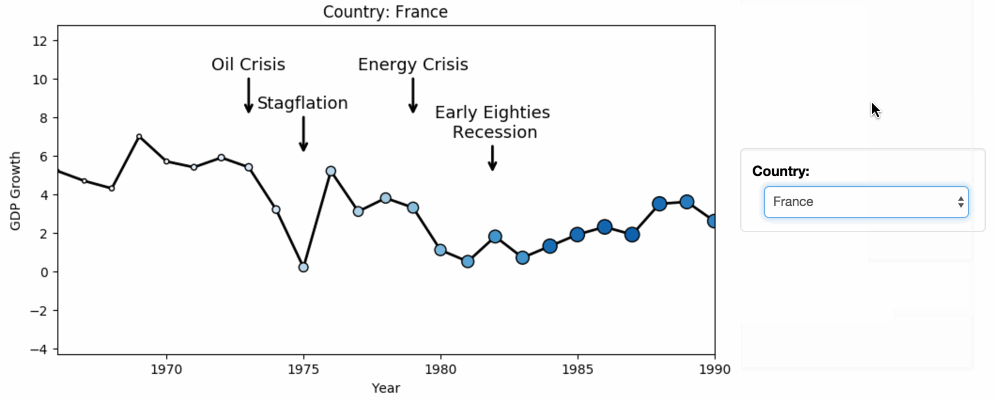
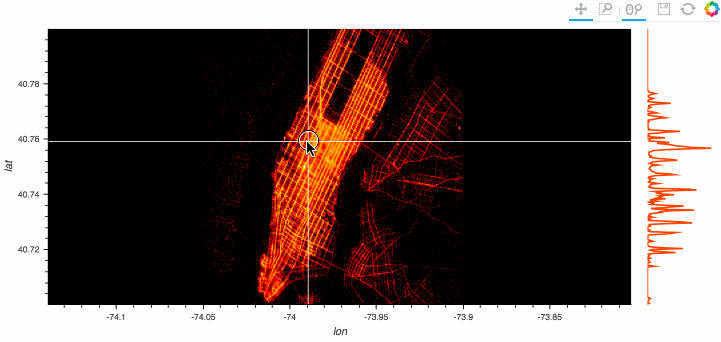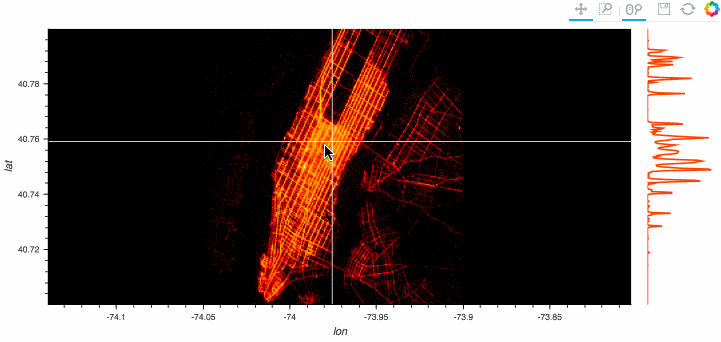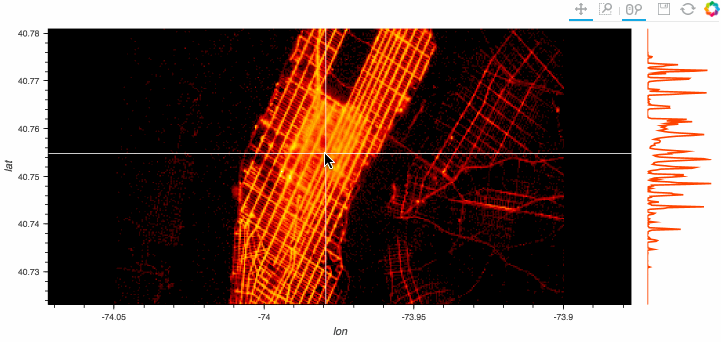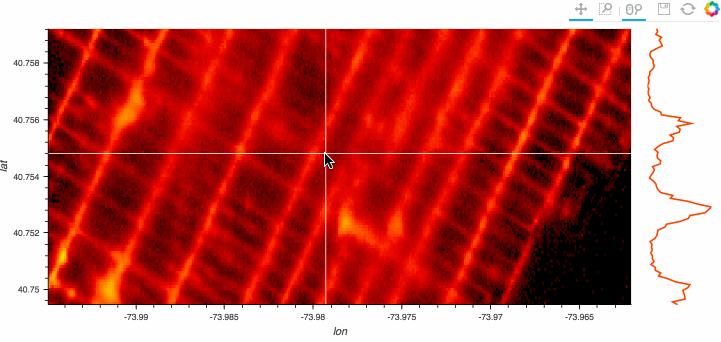
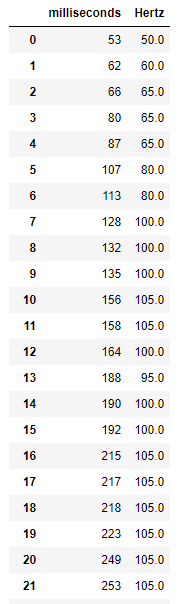
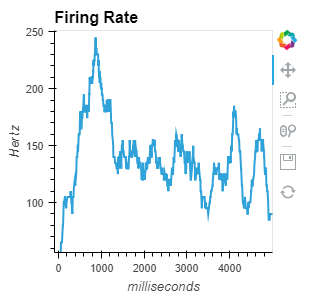
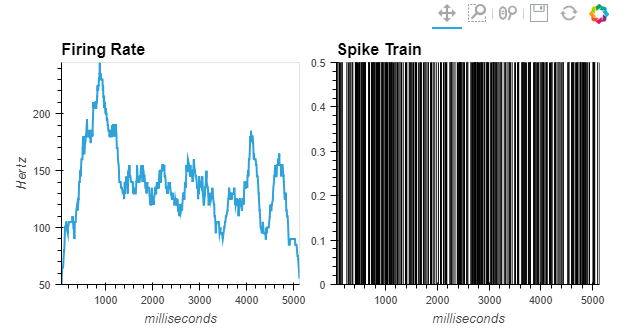
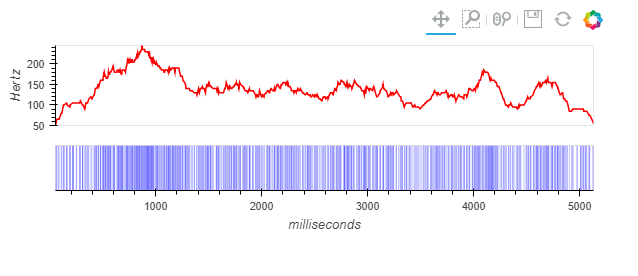
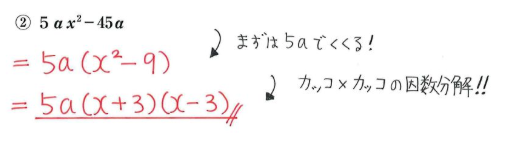dataframeに貿易統計のcsvを読み込ませる際に発生する文字化けを防ぐ
|
1 2 3 4 5 6 7 |
import numpy as np import pandas as pd import codecs with codecs.open("holoviews-master/examples/assets/zeikanhs.csv", "r", "Shift-JIS", "ignore") as file: df = pd.read_table(file, delimiter=",") df |