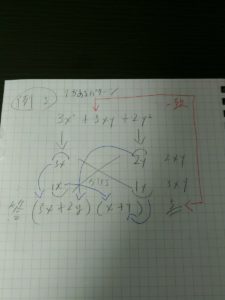

因数分解の公式

matplotlibでグラフをpngに変換
matplotlibでグラフをpngに変換
|
1 2 3 4 5 6 |
import matplotlib matplotlib.use("Agg") import matplotlib.pyplot as plt plt.plot([1,2,3,4,5,4,3,2,1]) plt.savefig("aaa.png") |
‘int’ object is not iterableが出た場合
‘int’ object is not iterableが出た場合forでin len()を設定すると
オブジェクトの数値が対象となってしまうのでin range()を使用する
|
1 |
for i in range((len(a))): |
複数のデータの訓練、テストスコアを比較
過学習でないかどうかを調べる
訓練セットスコアとテストセットの値が非常に近い場合は適合不足
0.9や1の場合は過学習を疑う
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
#決定木 from sklearn.tree import DecisionTreeClassifier ki = DecisionTreeClassifier(random_state=0).fit(train_X, train_y) print("ketteiki training score{:.2f}".format(ki.score(train_X,train_y))) print("ketteiki test score{:.2f}".format(ki.score(test_X,test_y))) #ランダムフォレスト from sklearn.ensemble import RandomForestClassifier mori = RandomForestClassifier(random_state=0).fit(train_X,train_y) print("mori training score{:.2f}".format(mori.score(train_X,train_y))) print("mori test score{:.2f}".format(mori.score(test_X,test_y))) #ロジスティック回帰 from sklearn.linear_model import LogisticRegression logi = LogisticRegression(C=100).fit(train_X,train_y) print("logi training score{:.2f}".format(logi.score(train_X,train_y))) print("logi test score{:.2f}".format(logi.score(test_X,test_y))) # #KNN from sklearn.neighbors import KNeighborsClassifier KNN = KNeighborsClassifier(4).fit(train_X,train_y) print("KNN training score{:.2f}".format(KNN.score(train_X,train_y))) print("KNN test score{:.2f}".format(KNN.score(test_X,test_y))) # #SVC from sklearn.svm import SVC svc = SVC(probability=True).fit(train_X,train_y) print("svc training score{:.2f}".format(svc.score(train_X,train_y))) print("svc test score{:.2f}".format(svc.score(test_X,test_y))) # #AdaBoostClassifier from sklearn.ensemble import AdaBoostClassifier ada = AdaBoostClassifier().fit(train_X,train_y) print("ada training score{:.2f}".format(ada.score(train_X,train_y))) print("ada test score{:.2f}".format(ada.score(test_X,test_y))) # #GradientBoostingClassifier from sklearn.ensemble import GradientBoostingClassifier gra = GradientBoostingClassifier().fit(train_X,train_y) print("gra training score{:.2f}".format(gra.score(train_X,train_y))) print("gra test score{:.2f}".format(gra.score(test_X,test_y))) # #GaussianNB from sklearn.naive_bayes import GaussianNB gaus = GaussianNB().fit(train_X,train_y) print("gaus training score{:.2f}".format(gaus.score(train_X,train_y))) print("gaus test score{:.2f}".format(gaus.score(test_X,test_y))) # #LinearDiscriminantAnalysis from sklearn.discriminant_analysis import LinearDiscriminantAnalysis lda = LinearDiscriminantAnalysis().fit(train_X,train_y) print("lda training score{:.2f}".format(lda.score(train_X,train_y))) print("lda test score{:.2f}".format(lda.score(test_X,test_y))) # #QuadraticDiscriminantAnalysis from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis qua = QuadraticDiscriminantAnalysis().fit(train_X,train_y) print("qua training score{:.2f}".format(qua.score(train_X,train_y))) print("qua test score{:.2f}".format(qua.score(test_X,test_y))) |
pipコマンド
パッケージインストール
|
1 2 3 4 5 6 7 8 9 |
python -m pip install <PackageName> or python -m pip install <PackageName>==<VersionNumber> or python -m pip install numpy==1.11.0 |
一括インストール
|
1 2 3 4 5 6 7 8 9 |
python -m pip install -r requirements.txt テキストを作成 requirements.txt numpy==1.11.0 six==1.10.0 |
パッケージのアンインストール
|
1 |
python -m pip uninstall <PackageName> |
インストール済みパッケージの確認
|
1 |
python -m pip freeze |
pipの有無
|
1 2 3 4 |
python -m pip -V pip 8.1.2 from C:¥python27¥lib¥site-packages (python 2.7)と出れば インストール済 |
pipのインストール
https://bootstrap.pypa.io/get-pip.py
からダウンロードしてから
|
1 |
python get-pip.py |
pipのアップグレード
|
1 |
python -m pip install --upgrade pip |