グラフのプロット
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import matplotlib.pyplot as plt import numpy as np # jupyterてグラフを表示する %matplotlib inline x = np.linspace(0, np.pi) y = np.sin(x) # データx,yをグラフにプロット plt.plot(x,y) plt.show() |
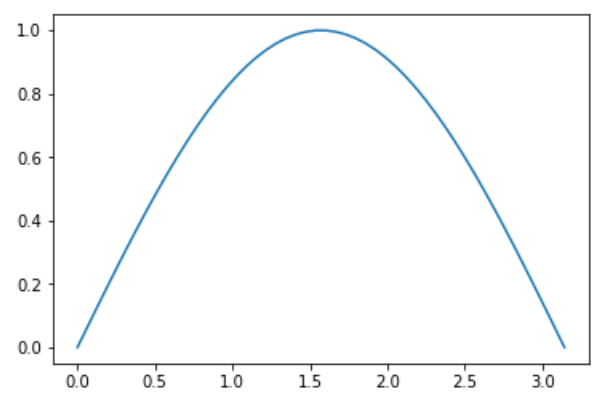
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import numpy as np import matplotlib.pyplot as plt %matplotlib inline days = np.arange(1, 11) weight = np.array([10, 14, 18, 20, 18, 16, 17, 18, 20, 17]) # 表示の設定 plt.ylim([0, weight.max()+1]) plt.xlabel("days") plt.ylabel("weight") # 円マーカーを赤色でプロットし、青の破線の折れ線グラフを作成 plt.plot(days, weight, linestyle="--", color="b", marker="o", markerfacecolor="r") plt.show() |
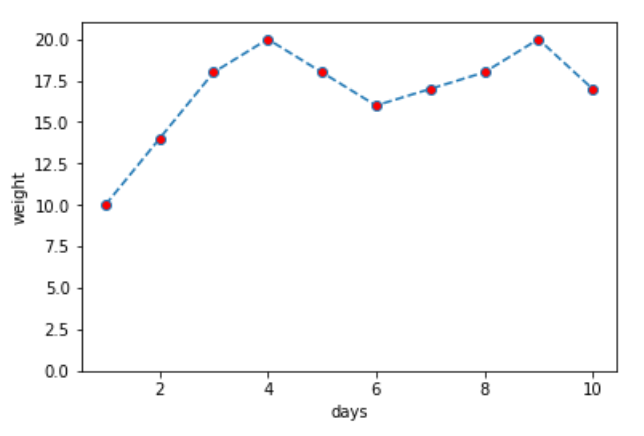
マーカー (,marker=”o”)
"o": 円"s": 四角"p": 五角形"*": 星"+": プラス"D": ダイアモンド
色 (markerfacecolor=”r”)
"b": 青"g": 緑"r": 赤"c": シアン"m": マゼンタ"y": 黄色"k": 黒"w": 白
線のスタイル (linestyle=”–“)
"-": 実線"--": 破線"-.": 破線(点入り)":": 点線