重複するデータを削除
|
1 2 3 4 5 6 7 |
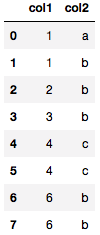
<span class="cm-keyword">import</span> <span class="cm-variable">pandas</span> <span class="cm-keyword">as</span> <span class="cm-variable">pd</span> <span class="cm-keyword">from</span> <span class="cm-variable">pandas</span> <span class="cm-keyword">import</span> <span class="cm-variable">DataFrame</span> <span class="cm-variable">dupli_data</span> = <span class="cm-variable">DataFrame</span>({<span class="cm-string">'col1'</span>:[<span class="cm-number">1</span>, <span class="cm-number">1</span>, <span class="cm-number">2</span>, <span class="cm-number">3</span>, <span class="cm-number">4</span>, <span class="cm-number">4</span>, <span class="cm-number">6</span>, <span class="cm-number">6</span>] ,<span class="cm-string">'col2'</span>:[<span class="cm-string">'a'</span>, <span class="cm-string">'b'</span>, <span class="cm-string">'b'</span>, <span class="cm-string">'b'</span>, <span class="cm-string">'c'</span>, <span class="cm-string">'c'</span>, <span class="cm-string">'b'</span>, <span class="cm-string">'b'</span>]}) <span class="cm-variable">dupli_data</span> |
duplicatedで縦の列同士、重複のある行にTrueかFalseがでる
|
1 2 |
<span class="cm-variable">dupli_data</span>.<span class="cm-property">duplicated</span>() |
|
1 2 3 4 5 6 7 8 9 10 |
0 False 1 False 2 False 3 False 4 False 5 True 6 False 7 True dtype: bool |
drop_duplicatesで重複したデータ削除
|
1 2 |
<span class="cm-variable">dupli_data</span>.<span class="cm-property">drop_duplicates</span>() |