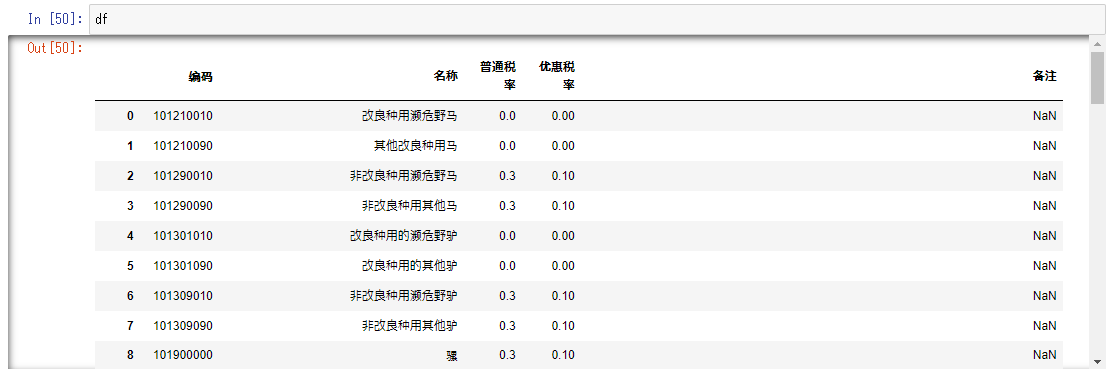
proxy経由でスクレイピングをする際はまずTORブラウザーをダウンロードする
ダウンロード
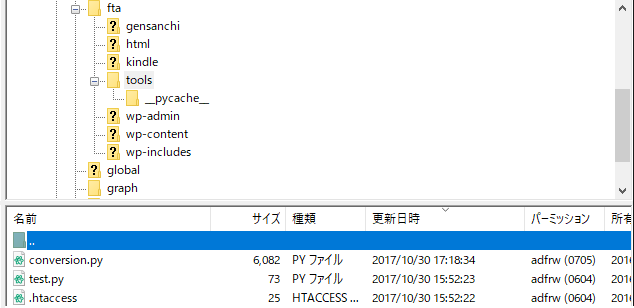
TORブラウザを起動させて右上の設定ボタンから
Option→Tor
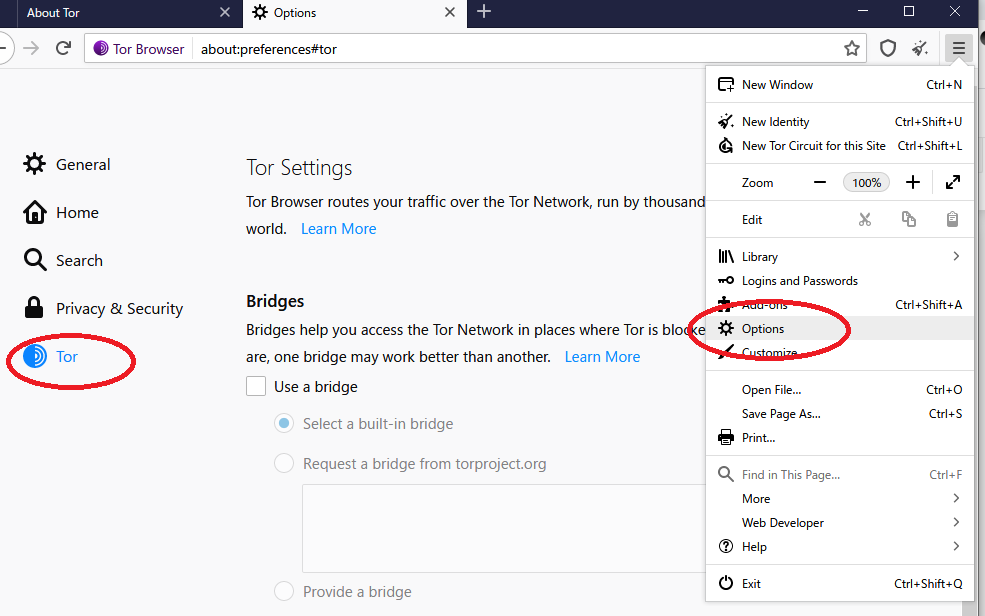
Advancedの設定
SOCKS 5 → 127.0.0.1 → 9150と入力
TORブラウザを起動させたままプログラムを実行
|
1 2 3 4 5 6 7 8 9 10 11 |
from selenium import webdriver from selenium.webdriver.chrome.options import Options chrome_options = Options() chrome_options.add_argument("--headless") chrome_options.add_argument("--proxy-server=socks5://127.0.0.1:9150") driver = webdriver.Chrome(options=chrome_options) # driver = webdriver.Chrome(executable_path='ChromeDriverPath', chrome_options=options) driver.get("http://icanhazip.com/") print(driver.page_source) driver.close() |
上記のコードで自分のPCと異なるIPアドレスが出てくれば準備OK
例:<html xmlns=”http://www.w3.org/1999/xhtml”><head></head><body><pre style=”word-wrap: break-word; white-space: pre-wrap;”>45.14.148.96</pre></body></html>
↓googleをスクレイピング
|
1 2 3 4 5 6 7 8 9 |
from selenium import webdriver from selenium.webdriver.chrome.options import Options chrome_options = Options() chrome_options.add_argument("--proxy-server=socks5://127.0.0.1:9150") driver = webdriver.Chrome(options=chrome_options) driver.get("http://google.com") driver.close() |
↓タイムアウトに対応
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
from selenium import webdriver from selenium.webdriver.chrome.options import Options import time chrome_options = Options() chrome_options.add_argument("--proxy-server=socks5://127.0.0.1:9150") driver = webdriver.Chrome(options=chrome_options) driver.get("http://google.com") time.sleep(2) i = 0 while i < 100: try: time.sleep(10) search_box = driver.find_element_by_id("TOPMENU_LNK_M_ULS0200000000") print("見つかったのでブレイク") break except: i = i + 1 print("再度トライ" + str(i) + "回目") driver.get("http://google.com") time.sleep(2) continue driver.close() |